Naive Bayes, kNN
Naive Bayes, kNN
정의
- 둘 다 model기반이 아닌, data 기반.
- 훈련데이터에서 예측한 비슷한 레코드를 기반으로 레코드를 분류
-
비슷한 레코드가 다른 방법으로 활용된다.
-
Naive Bayes
- 속성과 결과 범주 사이에 의존성 관계를 사용
- 통계를 기반으로한 학습과 분류 방법을 사용
- Bayes이론은 예측학습과 분류에서 중요한 역할을한다.
-
kNN
- 훈련데이터에서 주어진 레코드와 다른 레코드 사이의 거리를 사용
- 가장 가까운 거리의 k개의 투표를 연산한다.
-
Example
- 소비자가 안드로이드 폰을 살 것인가 아이폰을 살 것인가?
Naive Bayes(범주 예측)
- Gender와 Age에따라 안드로이드를 쓸 확률을 예측한다.
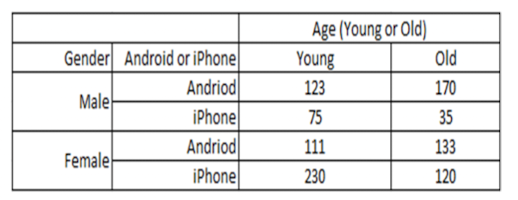)
kNN(지속적 예측)
- 새로운 소비자 X가 어떤 핸드폰을 살지 k neighbors로 투표해서 분류한다.

Naive Bayes
- Naive Bayes는 지도학습 중 범주형 응답, 법주형 예측으로 분류된다.
- 주어진 레코드가 분류되기위해선 비슷한 레코드를 찾아야한다.
- 이 레코드들 사이에서
자주 발생하는 범주가 무엇일까? - 이를 새로운 레코드에 할당한다.

Bayes Classifier의 기본개념
-
확률:
P(A = 1| B1, ...,Bp)- B의 값에따른 A가 1일 확률
-
이 확률은 조건부 확률로써, 아래와 같이 표현될 수 있다.

- 이 조건부확률은 역으로도 계산될 수 있다.
 단순 치환
단순 치환
 이 둘은 같으므로
이 둘은 같으므로
 조건부확률도 이렇게 다시 작성할 수 있다. 따라서
조건부확률도 이렇게 다시 작성할 수 있다. 따라서
 이고,
이고,
 이기때문에
이기때문에
 각각을 조건부확률로 바꾼다.
각각을 조건부확률로 바꾼다.
 따라서 조건부확률은 다음과같은 식이 만들어진다.
따라서 조건부확률은 다음과같은 식이 만들어진다.
Exact Bayes Classifier
- 레코드가 분류될 값과
같은 예측 값을 공유하는 다른 레코드를 찾는 것에 의존한다. - C라고 분류될 확률을 찾고자한다.
- 그러나,
큰 데이터셋에서도 레코드와 완벽하게 일치하는 레코드를 찾을 수 없다. - 그래서 Naive Bayes라는 간단한 기술을 사용한다.
Naive Bayes란?
- 각 범주의 예측 변수간 독립적이라고 가정한다.
- multiplication ruledmf tkdydgksek.
모든 동일한 값을 공유하는 레코드로 계산을 제한하지 않고- 주어진 예측 변수 값에서 레코드가 클래스 C에 속할 동일한 확률을 찾는다.
ex) Personal Loan Offer
- 고객 획득 노력의 일환으로, 유니버설 은행은 현재 고객들이 대출을 구입할 수 있도록 캠페인을 진행하려고 합니다.
- 타깃 마케팅을 개선하기 위해 개인 대출 제안을 수락할 가능성이 가장 높은 고객을 찾고자 합니다.
- 그들은 3,000명의 고객을 대상으로 한 이전 캠페인의 데이터를 사용하며, 그 중 286명이 이를 수락했습니다.

아래와 같은 확률을 구하고자한다.

방금 식을 적용하면 아래와 같은 식이된다.

따라서, 저 결과는
 이다.
이다.
Exact Naive Bayes의 어려움

- Exact Naive Bayes는 예측 카테고리의 모든 조합의 데이터가 있어야한다.
- 과거 데이터가 없다면, 예측 확률이 어긋날수있다.
- 이때는 Naive Bayes를 사용해야한다.
Exact to Naive Bayes
- 조건부확률에서 조건에 대한 각 확률이 독립적이라고 가정한다.
P(Y1=1, Y2=1|X=1)을P(Y1=1|X=1) * P(Y2=1|X=1)로 바꾼다는 의미.- 상관관계가 있어도 극단적이지만 않으면 사용할 수 있다.
example


댓글남기기