신경망(3) : Deep learning, RNN
RNN
- Recurrent Neural Network
Modeling Time Series
- RNN의 주 목표는
시계열 데이터의 분석이다.- 데이터는 일정 시간 간격으로 놓인다.
- 다음 상태를 예측하기 위한 수학적 모델을 만들어낸다.
- 시계열 모델링의 목표
- input: t state, output: t+1 state
- next state를 예측

- 보통은 이렇게
windowing방식으로 일정 기간의 데이터를 사용해 다음 주가를 에측한다.
Memoryless Model of Time Series Data
Autoregressive model

- 이전 input에 대해 고정 숫자 p를 사용한다.

- 데이터로부터 함수를 가장 잘 추정하는 파라미터
�\varphi(계수)를 결정하는 모델이다. -
\varepsilon _{t}을 허용한다. - 과거에 많이 사용되던 방식. 신경망 모델로 더 간단히 구현가능.
feed-forward neural nets

1개 이상의 비선형 hidden node를 사용한 AR 모델 정규화- 이전 input들을 넣어서 hidden node가 예측값을 학습한다.
- word2Vec
Memory needs model

Named entity recognition: 단어가 들어왔을때, 단어의 기능을 출력하는 문제.- 사람들의 이름, 지역, 조직 등을 input으로 넣어서 해당 단어가 어떤 명사인지 판단한다.
- 해당 단어가 사용되는 맥락에따라 다른 의미를 가지므로, 메모리가 필요하다.
메모리에 정보를 저장해문맥을 이해해야한다.- 모든 입출력은 의존적
- 결과는 이전 결과에 영향을 받는다.

RNN

- 메모리에 값을 저장하고 문맥을 이해해야한다는 특성을 구현하기위해서 만들어졌다.
- feed forward 신경망이라는건 비슷하지만, 중간층에 selfloop라고 부르는 자기자신과 자신을 잇는 신경망이 추가되었다.
- 시계열 데이터 처리, 다양한 길이의 입력 처리에 알맞다.
RNN Problem


- Gradient Vanishing
- 입력벡터, 출력벡터, 히든벡터가 있는데, 히든벡터에서 이전에 학습한 이전벡터를 반영한다.
- 그런데, 시간이 지남에따라 중요한 정보가 희석되는 문제가 발생한다.
Difficulty of RNN learning
- RNN기반 신경망은 쉽게 학습이 되지 않는다.

- 가중치가 조금만 바뀌어도 출력이 크게 변경되는 문제가 발생한다.

RNN의 부족한점
Long-term dependency problem- 시계열 데이터간 장기적 의존성때문.
- 멀리있는 값이 영향을 줘야하지만, 중첩으로 overlap되며 희석되는 문제
long term dependency Example- I grew up in
Franceand i speak fluentFrench - france와 french간 장기의존성이 발생.
- I grew up in
Long Short-Term Memory
- RNN의 Long-term dependency problem을 해결한다.

- 각 노드에
3개의 gate를 추가한다. input gate: 입력 받아들일지 말지output gate: 출력할지말지forget gate: 이전에 저장된 노드를 지울지말지
LSTM 아키텍처
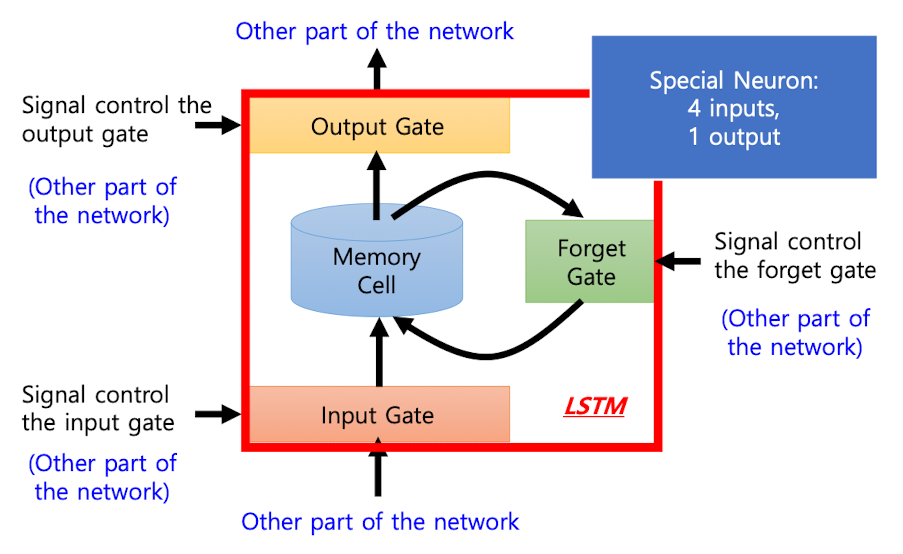)
1개의 노드에서 각 Gate에 가중치가 있고, 이에따라 입출력, 메모리 저장을 관리한다.
Machine Translation
- LSTM을 사용하면 언어번역에서 강점을 보인다.

Sequence to Sequence learning

- 고정 배열 입력 시퀀스를 사용해 출력 시퀀스를 만든다.
Encoder-decoder 조합 구조- 모든 input을 검사한 후에 output을 만든다.
- LSTM, GRU와 같은 RNN 셀들로 이뤄진다.
- 여전히
Long term dependency problem에 약점
Attention Mechanism

- Long term dependency problem을 해결한 메커니즘.
- input 벡터 각각에 다른 가중치를 할당한다.
- 한 번에 처리하는게 아닌, input 한개 한개에 가중치를 계산하는 방식.
- 이 input 별 초록색 점 가중치를
attention이라고한다.
Image Description with Attention
- Image caption
- 이미지를 문장으로 설명.
- Attention을 사용하면 문장의 어떤 단어가 왜 생겼는지 image상에서 표현된다.
CNN encoding - RNN decodingCNN으로 특징을 선택하고RNN으로 문장을 생성한다.
Bert와 Transformer
Bert

- 문장의 시퀀스를 집어넣어서 문장의 시퀀스가 출력되게하는데,
masked learning: 문장의 토큰하나하나를 마스킹해서 가림으로써 각 토큰의 가중치를 구한다.multitasking도 가능하다.
Transformer
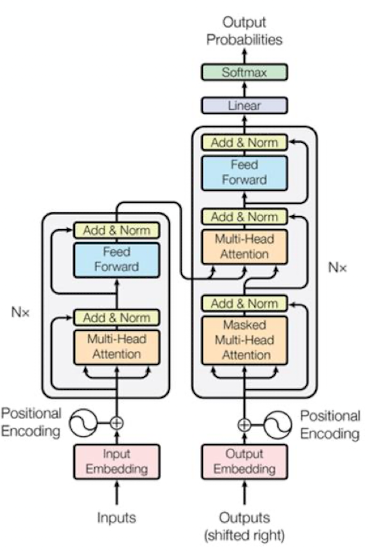)
- transformer의 encoder 파트를 N층을 쌓는다.
댓글남기기